1. 독립변수와 종속변수의 관계 살펴보기 - scatter plot
import pandas as pd
import seaborn as sns
from matplotlib import pyplot as plt
from sklearn.model_selection import train_test_split
#df
sns.pairplot(df[["MEDV", "RM", "AGE", "CHAS"]])
plt.show()
#X
#y
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)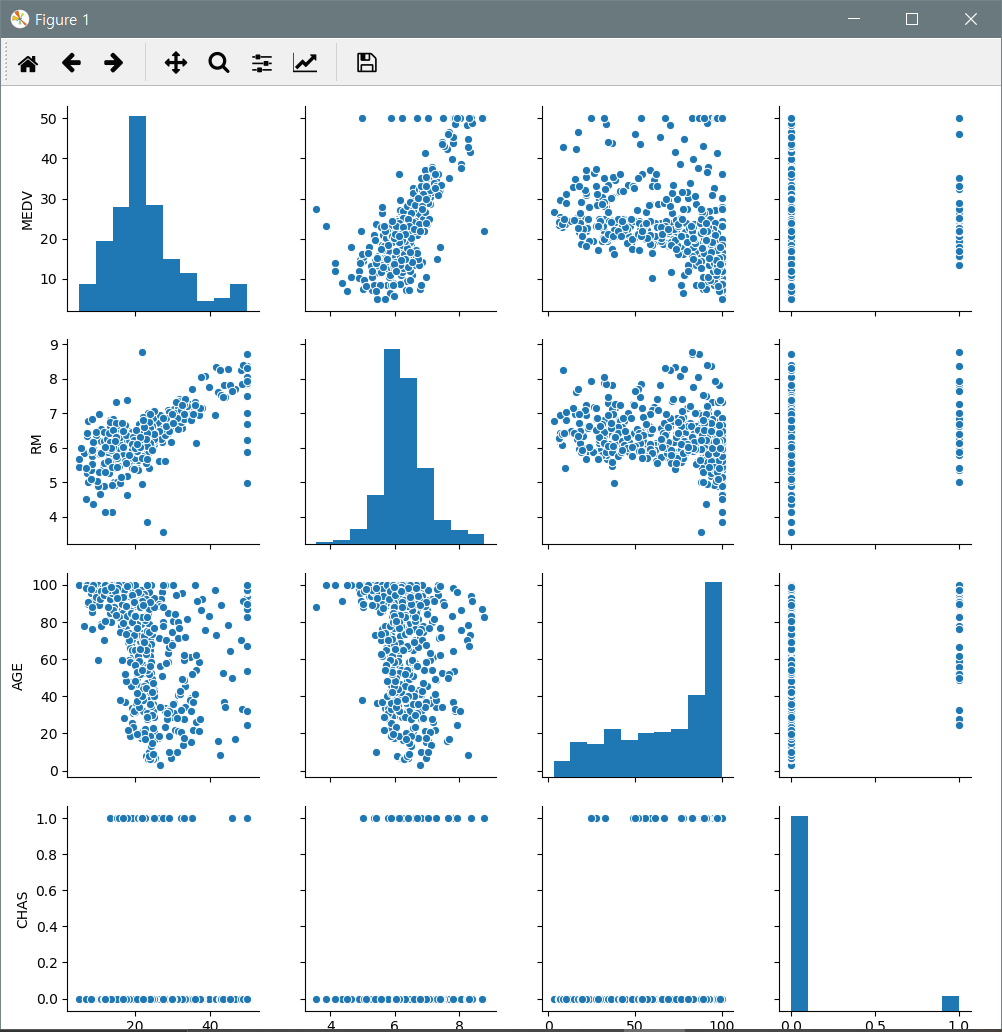
2. 선형회귀 - scikit-learn, statsmodels 패키지 비교
- scikit-learn은 상수항 결합을 자동으로 해줘 add_constant 등의 상수항 결합 필요없음
- statsmodels에서 from_formula 함수를 쓰면 상수항 결합이 필요없지만 x, y로 데이터를 나눴을 시에는 add_constant 를 사용해 수동으로 상수항 결합해줘야 함
- statsmodels에서 예측을 위한 데이터 또한 추정시와 동일하게 상수항 결합을 해 주어야 한다.
- statsmodels 패키지의 장점
회귀결과를 보여주며 p-value, R^2 등의 결과를 쉽게 파악할 수 있고
잔차벡터의 결과를 볼 수 있어 잔차 plot을 그릴 수 있다.
(1) scikit-learn 패키지를 사용한 선형회귀
from sklearn.linear_model import LinearRegression
# LinearRegression 모델 코드
model = LinearRegression() # fit_intercept 인수가 항상 True로 상수항 있음
model.fit(X_train, y_train) # 상수항 결합 자동 -> add_constant 할 필요 없음
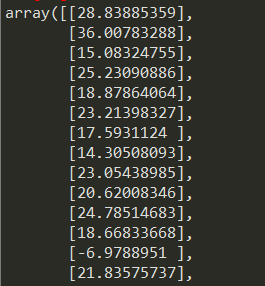
predict_y = model.predict(X_test)
print("가중치(계수, 기울기 파라미터 W) :", model.coef_)
print("편향(절편 파라미터 b) :", model.intercept_)
print("훈련세트 점수: {:.2f}".format( model.score(X_train, y_train) ))
print("테스트세트 점수: {:.2f}".format( model.score(X_test, y_test) ))

(2) statsmodels 패키지를 사용한 선형회귀
import statsmodels.api as sm
dfX = sm.add_constant(X_train) # 절편 / 상수항 추가
model = sm.OLS(y_train, dfX)
results = model.fit()
X_new = sm.add_constant(X_test) # 절편 / 상수항 추가
predict_y = result.predict(X_new)
result.params # coef 확인
results.summary() # coef, p-value, R^2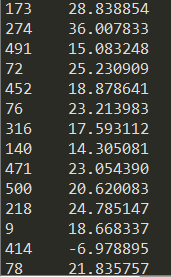

- 잔차 plot
from matplotlib import font_manager, rc
font_name = font_manager.FontProperties(fname="c:/Windows/Fonts/malgun.ttf").get_name()
rc('font', family=font_name)
results.resid.plot(style="o")
plt.title("잔차 벡터")
plt.xlabel("데이터 번호")
plt.ylabel("잔차")
plt.show()
'Analysis > ML' 카테고리의 다른 글
| [sklearn] 교차 검증 (0) | 2021.05.11 |
|---|---|
| [sklearn] 특성 공학 (0) | 2021.05.11 |
| [sklearn] 비지도학습 (0) | 2021.05.10 |
| [sklearn] 지도학습 (0) | 2021.05.10 |
댓글