1. 전제조건
- 품목 : 컴퓨터
- 가격대별로 5개의 상품
2. 데이터 정보
- customer_master.csv : 고객 정보
(customer_id, customer_name, registration_date, email, gender, age, birth, pref)

- item_master.csv : 상품 데이터
(item_id, item_name, item_price)
- transaction_1.csv / transaction_2.csv 구매내역 데이터
(transaction_id, price, payment_date, customer_id)
- transaction_detail_1.csv / transaction_detail_2.csv : 구매 상세 데이터
(detail_id, transaction_id, item_id, quantity)

import os
import pandas as pd
import matplotlib.pyplot as plt
os.chdir('C:\\Users\\leeso\\Downloads\\pyda100-master\\1장')
# [행, 열]
customer_master = pd.read_csv('customer_master.csv') #[5000,8]
item_master = pd.read_csv('item_master.csv') #[5,3]
transaction_1 = pd.read_csv('transaction_1.csv') #[5000,4]
transaction_2 = pd.read_csv('transaction_2.csv') #[1786,4]
transaction_detail_1 = pd.read_csv('transaction_detail_1.csv') #[5000,4]
transaction_detail_2 = pd.read_csv('transaction_detail_2.csv') #[2144,4]
3. 데이터 준비
(1) transaction_*.csv 데이터와 transaction_detail_*.csv 데이터 파일 통합시키기 ( pd.concat )
transaction=pd.concat([transaction_1,transaction_2],ignore_index=True) #[6786,4]
transaction_detail=pd.concat([transaction_detail_1,transaction_detail_2],ignore_index=True) #[7144,4]
(2) 공통으로 가지고 있는 컬럼을 이용해 merge 시키기
- transaction_detail 데이터가 가장 크고 자세한 데이터이므로 기준 데이터로 사용
- how = 'left' 나 'outer' > 똑같은 결과
- 다른 결과일 시에는 두 데이터끼리 key가 일치하지 않는 경우 -> 살펴보고 drop 결정
merge_data_1=pd.merge(transaction_detail,transaction,on='transaction_id',how='left') #[7144,7]
merge_data_2=pd.merge(merge_data_1,item_master,on='item_id',how='left') #[7144,9]
merge_data_3=pd.merge(merge_data_2,customer_master,on='customer_id',how='left') #[7144,16]
4. 데이터 가공
- 데이터를 살펴보니 detail_id 마다의 가격을 구할 수 있음
- detail_price= quatity * item_price
- price = transaction_id 의 detail_price 총합
merge_data_3['detail_price']= merge_data_3['quantity']*merge_data_3['item_price']
# 검산과정 : 다 같은 결과
transaction['price'].sum()
merge_data_3['detail_price'].sum()
merge_data_3.drop_duplicates('transaction_id')['price'].sum()
5. 데이터 분석
- NA값 파악 -> 없음
- 각종 통계량 파악
merge_data_3.isnull().sum()
merge_data_3[['quantity','price','item_price','age','detail_price']].describe()
6. 월별 데이터 집계
- pandas의 datetime의 dt 사용해 년, 월 추출
- 월별 매출 구하기 > 2019/05 매출이 가장 낮고, 2019/07 매출이 가장 높음
merge_data_3.dtypes
merge_data_3['payment_date'] = pd.to_datetime(merge_data_3['payment_date'])
merge_data_3['payment_date'].min()
merge_data_3['payment_date'].max()
merge_data_3['payment_month']=merge_data_3['payment_date'].dt.strftime('%Y%m') #대문자 %Y는 2019 / %y는 19
merge_data_3.groupby("payment_month").sum()['detail_price']
7. 월별, 상품별로 데이터 집계
- groupby
- pivot_table : values가 나눠서 보여 직관적임
merge_data_3.groupby(['item_name','payment_month']).sum()[['quantity','detail_price']]
pd.pivot_table(merge_data_3,index='item_name',columns='payment_month',values=['detail_price','quantity'],aggfunc='sum')
8. 그래프로 나타내기
- pivot_graph.index : ['201902', '201903', '201904', '201905', '201906', '201907']
pivot_graph = pd.pivot_table(merge_data_3,index='payment_month',columns='item_name',values='detail_price',aggfunc='sum')
plt.plot(list(pivot_graph.index), pivot_graph['PC-A'], label='PC-A') # x축, y축, 범례 이름
plt.plot(list(pivot_graph.index), pivot_graph['PC-B'], label='PC-B')
plt.plot(list(pivot_graph.index), pivot_graph['PC-C'], label='PC-C')
plt.plot(list(pivot_graph.index), pivot_graph['PC-D'], label='PC-D')
plt.plot(list(pivot_graph.index), pivot_graph['PC-E'], label='PC-E')
plt.legend()
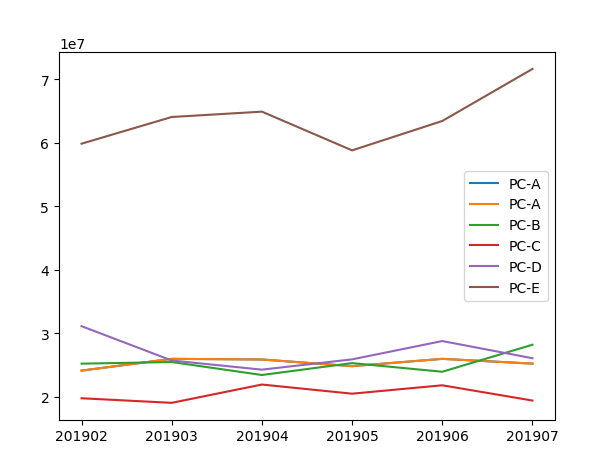
9. 결론
- 매출 추이 파악 및 PC-E가 매출을 견인하는 상품
10. 참고 자료 및 출처
- 책 <파이썬 데이터 분석 실무 테크닉 100>
- 데이터 github.com/wikibook/pyda100
'Analysis > Example' 카테고리의 다른 글
| 물류 데이터 분석 - 데이터 가공, 통계량 파악 (0) | 2021.02.15 |
|---|---|
| 스포츠센터 회원 분석 - 의사결정나무 (0) | 2021.02.07 |
| 스포츠센터 회원 분석 - 클러스터링, 회귀분석 (0) | 2021.01.30 |
| 스포츠센터 회원 분석 - 데이터 가공, 통계량 파악 (0) | 2021.01.30 |
| 대리점 데이터 분석 (0) | 2021.01.29 |




댓글