1. 전제조건
- 스포츠센터 고객분석 데이터 사용
- 행동 패턴을 분석할 수 있으면 어떤 회원이 탈퇴할지 예측도 가능
- 탈퇴 회원이 왜 탈퇴했는지 분석
[ 이전글 ]
2021/01/30 - [Data/Data Analysis] - 스포츠센터 회원 분석 - 데이터 가공, 통계량 파악
스포츠센터 회원 분석 - 데이터 가공, 통계량 파악
1. 전제조건 (1) 3가지의 회원권 종류 종일회원 : 언제든 사용할 수 있음 주간회원 : 낮에만 사용가능 야간회원 : 밤에만 사용가능 (2) 입회비 일반적으로는 입회비 비용 있음 비정기적으로 입회비
5ohyun.tistory.com
2021/01/30 - [Data/Data Analysis] - 스포츠센터 회원 분석 - 클러스터링, 회귀분석
스포츠센터 회원 분석 - 클러스터링, 회귀분석
1. 전제조건 스포츠센터 고객분석 데이터 사용 고객별 이용 횟수 등의 예측 2021/01/30 - [Data Analysis] - 스포츠센터 회원 분석 - 데이터 가공, 통계량 파악 스포츠센터 고객분석 1. 전제조건 (1) 3가지
5ohyun.tistory.com
2. 데이터 정보
- use_log_months.csv
- customer.csv
import os
import pandas as pd
import matplotlib.pyplot as plt
os.chdir('C:\\Users\\leeso\\Downloads\\pyda100-master\\3장')
customer = pd.read_csv('customer.csv')
use_log_months = pd.read_csv('use_log_months.csv')
3. 탈퇴회원과 지속회원의 차이점 알아보기
(1) 회원의 전월 사용량 집계
- 탈퇴회원들 중에는 빠르게 탈퇴하는 사람들이 많았기에 일단 전월데이터만 살펴보기
yearmonth = use_log_months['useYm'].unique()
uselog = pd.DataFrame()
for i in range(1,len(yearmonth)) :
tmp = use_log_months.loc[use_log_months['useYm']==yearmonth[i]] # 해당월의 사람들 다 산출
tmp = tmp.rename(columns={'count':'count_0'})
tmp_before = use_log_months.loc[use_log_months['useYm']==yearmonth[i-1]]
del tmp_before['useYm']
tmp_before= tmp_before.rename(columns={'count':'count_1'}) # 전월 데이터
tmp=pd.merge(tmp,tmp_before,on='customer_id',how='left')
uselog=pd.concat([uselog,tmp],ignore_index=True)
(2) 탈퇴회원 집계
- end_date는 탈퇴처리가 된 달이므로 탈퇴신청을 한 달인 end_date 전 달 기준으로 탈퇴회원 데이터를 만들어야 함
- 탈퇴회원의 목록과 전월 사용량 데이터 merge
from dateutil.relativedelta import relativedelta
delete_customer=customer.loc[customer['is_deleted']==1]
delete_customer = delete_customer.reset_index(drop=True)
delete_customer['exit_date'] = None
delete_customer['end_date'] = pd.to_datetime(delete_customer['end_date'])
for i in range(len(delete_customer)) :
delete_customer['exit_date'][i] = delete_customer['end_date'].iloc[i] - relativedelta(months=1)
delete_customer['useYm'] = delete_customer['exit_date'].dt.strftime('%Y%m')
delete_customer['useYm']= delete_customer['useYm'].astype(str)
uselog['useYm']= uselog['useYm'].astype(str)
delete_uselog = pd.merge(uselog, delete_customer,on=['customer_id','useYm'],how='left')
delete_uselog = delete_uselog.dropna(subset=['name']) #count가 지워지지않게
지속회원의 데이터가 nan값으로 채워지고
NA값을 제거할 때는 사용량 데이터가 없어지지 않도록 name을 기준으로 drop한다
(3) 지속회원 집계 및 합치기
conti_customer=customer.loc[customer['is_deleted']==0]
conti_customer = conti_customer.reset_index(drop=True)
conti_uselog = pd.merge(uselog, conti_customer,on='customer_id',how='left')
conti_uselog = conti_uselog.dropna(subset=['name']) #count가 지워지지않게
len(conti_uselog['customer_id'].unique())
- 현재 탈퇴회원의 데이터가 1104밖에 없고 지속회원은 27422개이므로 한 쪽의 데이터가 몇 %밖에 없는 경우 샘플의 수를 조정한다.
- 지속회원데이터에서 회원당 1개의 log를 가지도록 언더샘플링 - 랜덤으로 섞어 중복을 제거할 것이다.
conti_uselog = conti_uselog.sample(frac=1).reset_index(drop=True)
conti_uselog = conti_uselog.drop_duplicates(subset='customer_id')
- 데이터를 합쳐준다. [3946,22]
predict_data=pd.concat([conti_uselog,delete_uselog],ignore_index=True)
4. 변수 추가
- 재적기간 변수 추가 - 시간적 요소
- None으로 열을 만들었을때 object로 인식하기 때문에 type 바꿔주어야 함
predict_data['useYm'] = pd.to_datetime(predict_data['useYm'],format='%Y%m')
predict_data['start_date'] = pd.to_datetime(predict_data['start_date'])
predict_data['period'] = None
for i in range(len(predict_data)) :
delta=relativedelta(predict_data['useYm'][i],predict_data['start_date'][i])
predict_data['period'][i] = int(delta.years*12 +delta.months)
predict_data['period']=predict_data['period'].astype(int)
5. 데이터 처리
(1) 결측치 제거
- end_date와 exit_date는 기존 회원일시에 존재하지 않아 결측치가 맞음
- count_1이 없는 경우엔 가입한 지 1달밖에 되지않는 것으로 전 달이 없는 기존회원의 데이터로 제거
predict_data=predict_data.dropna(subset=['count_1'])
(2) 변수 처리
- 예측에 사용할 열 추출
target_col = ['campaign_name','class_name','gender','count_1','routine','period','is_deleted']
predict_data = predict_data[target_col]
predict_data
- 더미변수 생성 - pd.get_dummies
- 중복되는 더미 변수 제거
( 3개의 campaign_name, 3개의 class_name, 2개의 gender에서 하나씩 제거 ) -> 총 9개의 열
predict_dummy = pd.get_dummies(predict_data)
del predict_data['campaign_name_일반']
del predict_data['class_name_야간']
del predict_data['gender_M']
6. 의사결정트리 Decision Tree
(1) sklearn 의 DecisionTreeClassifier
- 유지회원 데이터의 수를 탈퇴회원 데이터의 수와 맞춰 모델링
- X, y 로 train, test set 나눠 fitting
from sklearn.tree import DecisionTreeClassifier
import sklearn.model_selection
deleted = predict_dummy.loc[predict_dummy['is_deleted']==1]
conti = predict_dummy.loc[predict_dummy['is_deleted']==0].sample(len(deleted)) # 비율 1:1로 맞춤
X = pd.concat([deleted,conti],ignore_index = True)
y = X['is_deleted']
del X['is_deleted']
X_train, X_test, y_train, y_test = sklearn.model_selection.train_test_split(X,y)
model = DecisionTreeClassifier(random_state=0)
model.fit(X_train,y_train)
y_test_pred = model.predict(X_test)
(2) 실제 결과값과 비교
- train과 test가 많이 차이나며 train 데이터에 과적합
- 튜닝 필요
model.score(X_train, y_train) # 0.98
model.score(X_test,y_test) # 0.89
7. 모델 튜닝
- 과적합 해결하기 위해서는 데이터 늘리기, 변수 재검토, 모델 파라미터 변경 등의 방법 사용
- 트리 깊이를 얕게 만들어 모델 단순화 하기 (max_depth)
model = DecisionTreeClassifier(random_state=0, max_depth=5)
model.fit(X_train,y_train)
model.score(X_train, y_train) # 0.93
model.score(X_test,y_test) # 0.91
8. 모델 기여 변수 확인
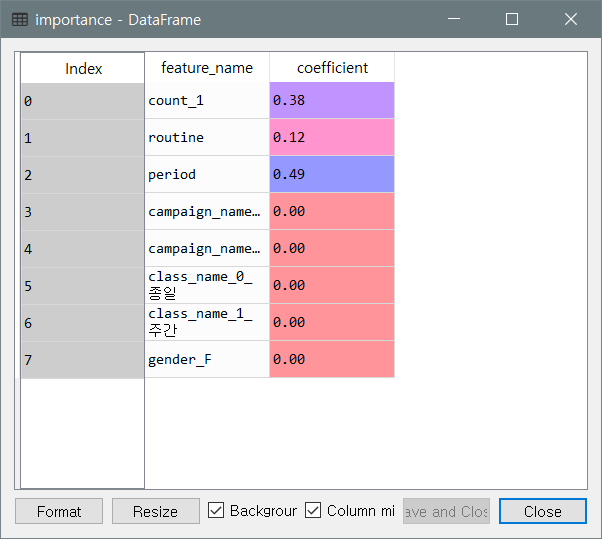
- 분류에 기여하는 변수 - 1개월 전의 이용 횟수, 정기 이용 여부, 재적 기간
importance = pd.DataFrame({'feature_name':X.columns,'coefficient':model.feature_importances_})
+ 참고 자료 및 출처
- 책 <파이썬 데이터 분석 실무 테크닉 100>
- 데이터 github.com/wikibook/pyda100
'Analysis > Example' 카테고리의 다른 글
| 물류 비용 최소화 - 네트워크 가시화, 최적화 (0) | 2021.02.15 |
|---|---|
| 물류 데이터 분석 - 데이터 가공, 통계량 파악 (0) | 2021.02.15 |
| 스포츠센터 회원 분석 - 클러스터링, 회귀분석 (0) | 2021.01.30 |
| 스포츠센터 회원 분석 - 데이터 가공, 통계량 파악 (0) | 2021.01.30 |
| 대리점 데이터 분석 (0) | 2021.01.29 |




댓글