<1> 에서는 BI의 의미와 빅데이터를 시각화하기까지의 대략적 과정을,
<2편> 에서는 데이터를 시각화하기 위한 데이터 마트 준비 과정을 살펴보았습니다.
<1. 빅데이터의 기초 지식> BI란 무엇일까요?
대학생때 태블로를 들어보기는 했지만 해당 툴을 실제 기업에서 쓸 거라고는 생각도 못했던 것 같습니다. 우선 데이터를 시각화해서 보고자 하는 요구가 존재할까? 에 대한 의문이 있었는데요.
5ohyun.tistory.com
<2. 빅데이터의 탐색> 시각화(BI)하기 위한 데이터 준비
빅데이터를 시각화(BI)하기까지의 과정에 이어 작성합니다. 빅데이터를 시각화(BI)하기까지의 과정 대학생때 태블로를 들어보기는 했지만 해당 툴을 실제 기업에서 쓸 거라고는 생각도 못했던
5ohyun.tistory.com
1. 데이터의 구조
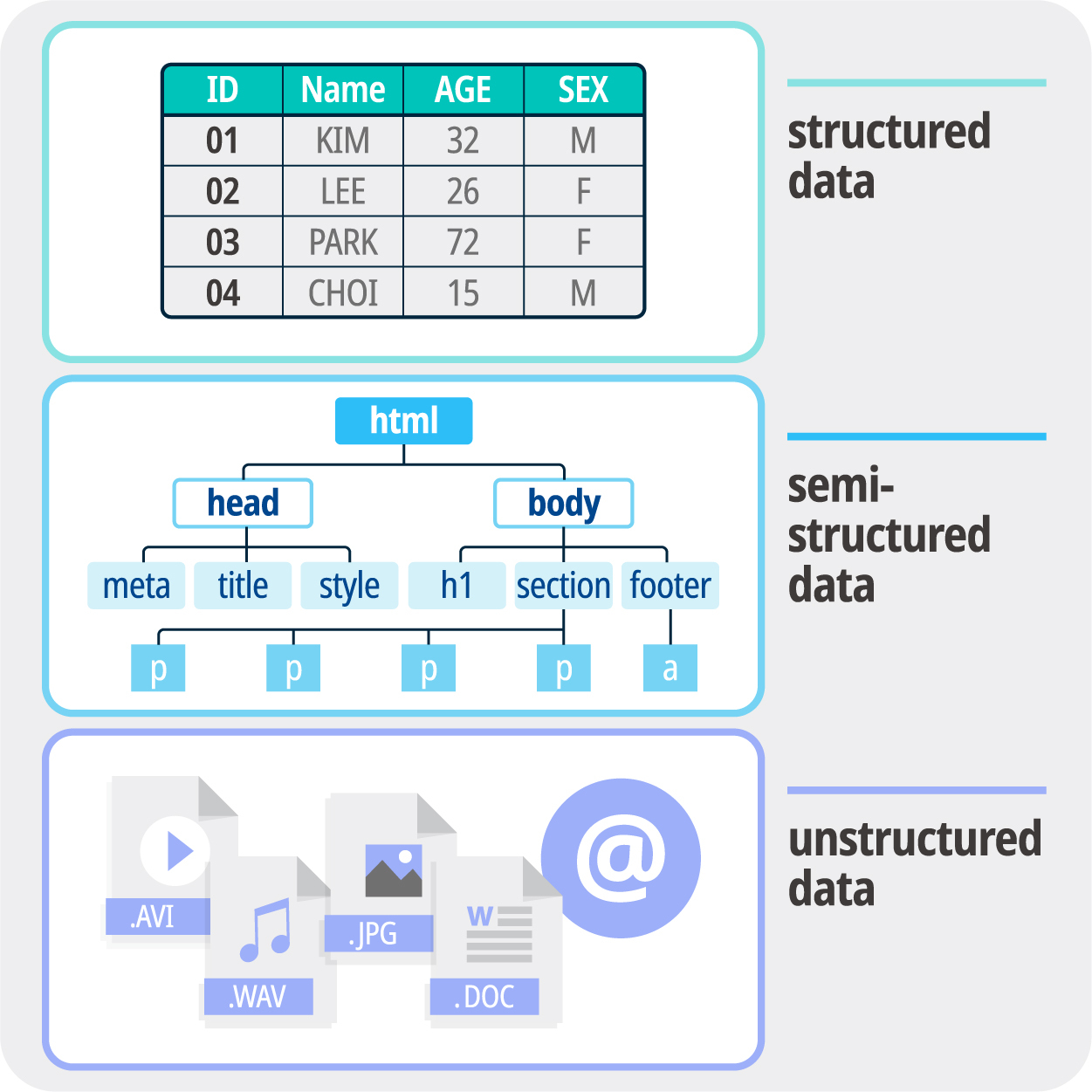
먼저 데이터의 구조를 나눠서 본다면 구조화 데이터와 비구조화 데이터, 스키마리스 데이터로 나눌 수 있습니다.
1) 구조화 데이터는 SQL로 데이터를 집계할 때 테이블의 컬럼명, 데이터형, 테이블 간의 관계 등을 스키마로 정하는데 명확하게 스키마가 정의된 데이터를 말합니다.
2) 비구조화 데이터는 텍스트 데이터, 이미지,동영상 등 이러한 스키마가 없는 데이터이며 SQL로 집계할 수가 없는 형태입니다.
비구조화 데이터를 분산 스토리지 (여러 컴퓨터와 디스크로 구성) 등에 저장하고 분산 시스템에서 처리하는 것이 데이터 레이크입니다. 데이터를 가공하며 스키마를 정의하고 구조화된 데이터로 변환하며 다른 데이터처럼 분석할 수 있습니다.
3) 스키마리스 데이터는 CSV, JSON, XML 등의 데이터처럼 서식은 있지만 컬럼 수나 데이터형이 따로 정해지지 않은 형태를 말합니다. JSON, XML 등은 명시적으로 스키마를 정할 수도 있어서 반구조화 데이터이기도 합니다.
스키마리스 데이터와 비구조화 데이터는 처음엔 분산 스토리지에 보존되고 이를 테이블 형태의 구조화 데이터로 변환합니다. 구조화 데이터는 이전 글에서 나온 바와 같이 MPP 데이터베이스로 전송하거나 hadoop 상에서 열 지향 스토리지로 변환, 저장합니다. 시간에 따라 증가하는 테이블을 팩트 테이블, 부속 데이터를 디맨젼 테이블로 구조화해서 SQL로 집계 가능한 테이블을 만듭니다.
MPP의 경우에는 스토리지 형식이 고정되어있어서 상세하게 사용자가 방법을 몰라도 되지만, hadoop의 경우에는 사용자가 직접 열 지향 스토리지의 형식을 선택해 원하는 쿼리 엔진에서 집계할 수 있도록 합니다.
- Hadoop
다수의 컴퓨터에서 대량의 데이터를 처리하기 위한 시스템으로 단일 소프트웨어가 아니라 분산 시스템을 구성하는 다수 소프트웨어로 이루어진 집합체입니다.
https://www.databricks.com/kr/glossary/hadoop
What is Hadoop? – Databricks
하둡이란 무엇입니까? "하둡"이란 무엇을 의미할까요? 더 중요한 것은, "하둡"은 무엇의 약자일까요? 사실, 고가용성 분산형 객체 지향적 플랫폼(High Availability Distributed Object Oriented Platform)을 뜻합
www.databricks.com
https://www.tableau.com/ko-kr/learn/articles/big-data-hadoop-explained
빅 데이터와 Hadoop이 자주 함께 거론되는 이유
빅 데이터와 Hadoop이 자주 함께 거론되는 이유
www.tableau.com

분산 시스템의 구성 요소를 먼저 HDFS, YARN, MapReduce 3가지로 나눌 수 있습니다. 이외의 프로젝트들은 하둡과 독립적으로 개발되어서 하둡을 이용한 분산 애플리케이션으로 동작합니다.
- HDFS (분산 파일 시스템) : 하둡에서 처리되는 데이터 대부분이 저장되는 곳이며 네트워크에 연결된 파일 서버와 같은 공간이지만 다수의 컴퓨터에 파일을 복사해 중복성을 높입니다.
- YARN (리소스 관리자) : CPU나 메모리 등의 계산 리소스를 관리하며 애플리케이션이 사용하는 CPU 코어와 메모리를 컨테이너라고 불리는 단위로 관리합니다. 분산 애플리케이션을 실행하면 클러스터의 전체적인 부하를 보고 비어있는 호스트로부터 컨테이너를 할당합니다. 애플리케이션마다 실행 우선순위를 결정할 수 있으며 리소스를 낭비없이 사용할 수 있도록 처리 진행합니다.
- MapReduce (분산 데이터 처리) : YARN 상에서 동작하는 분산 애플리케이션 중 하나이며 임의의 자바 프로그램을 실행시킬 수 있기 때문에 비구조화 데이터를 가공하는데 적합합니다. 쿼리를 자동으로 MapReduce 프로그램으로 변환하는 소프트웨어인 Hive가 존재하며, MapReduce는 비구조화 데이터를 가공하는 무거운 대량의 데이터를 배치 처리하기 위한 시스템에 적합하며 애드 혹 쿼리를 여러번 실행하는 것에는 부적합합니다.
- 대화형 쿼리 엔진 (Impala, Presto) : Hive를 고속화하는 것이 아닌 처음부터 대화형 쿼리 실행을 할 수 있도록 하는 쿼리 엔진입니다. 순간 최대 속도를 높이기 위해 모든 오버헤드를 제거해 사용할 수 있는 리소스를 최대한 활용해 쿼리를 실행합니다.

해당 내용은 < 빅데이터를 지탱하는 기술 - 니시다 케이스케 >
3. 빅데이터의 분산 처리를 참고하여 작성했습니다.
4. 빅데이터의 축적
5. 빅데이터의 파이프라인
6. 빅데이터 분석 기반의 구축
순서로 정리하고자 합니다.
감사합니다😄
'Visualization > BI - DW' 카테고리의 다른 글
| <2. 빅데이터의 탐색> 시각화(BI)하기 위한 데이터 마트 준비 (0) | 2023.04.23 |
|---|---|
| <1. 빅데이터의 기초 지식> BI란 무엇일까요? (3) | 2023.03.26 |
| [seaborn] Color palette (0) | 2021.07.22 |
| [nbviewer] jupyter notebook 사이트 내 표시 (0) | 2021.07.21 |




댓글