0. 데이터 형태
- 비트코인 가격만 있는 데이터
- 60일치 데이터로 예측 목표
(1) 데이터 정제
# Parameters
criteria = '2020-01-01'
scaler = preprocessing.MinMaxScaler()
sequence = 60
batch_size = 32
epoch = 10
verbose = 1
dropout_ratio = 0# Train & Test Split
train = raw_all.loc[raw_all.index < criteria,:]
test = raw_all.loc[raw_all.index >= criteria,:]
print('Train_size:', train.shape, 'Test_size:', test.shape)
- 2020-01-01 기준으로 train, test split
- train : 2017-01-01 ~ 2019-12-31
- test : 2020-01-01 ~ 2020-10-31
# Scaling
train_scaled = scaler.fit_transform(train)
test_scaled = scaler.transform(test)
- min-max scaler
- scaling시에 train set은 fit_transform, test set은 transform 적용
- train 기준으로 test set 스케일링 필요
# X / Y Split
X_train, Y_train = [], []
for index in range(len(train_scaled) - sequence):
X_train.append(train_scaled[index: index + sequence])
Y_train.append(train_scaled[index + sequence])
X_test, Y_test = [], []
for index in range(len(test_scaled) - sequence):
X_test.append(test_scaled[index: index + sequence])
Y_test.append(test_scaled[index + sequence])
- 60일 기준으로 다음날 비트코인 가격 예측하는 것으로 설정
# Retype and Reshape
X_train, Y_train = np.array(X_train), np.array(Y_train)
X_test, Y_test = np.array(X_test), np.array(Y_test)
print('X_train:', X_train.shape, 'Y_train:', Y_train.shape)
print('X_test:', X_test.shape, 'Y_test:', Y_test.shape)
1. MLP
# MLP
X_train = X_train.reshape(X_train.shape[0], X_train.shape[1])
X_test = X_test.reshape(X_test.shape[0], X_test.shape[1])
print('Reshaping for MLP')
print('X_train:', X_train.shape, 'Y_train:', Y_train.shape)
print('X_test:', X_test.shape, 'Y_test:', Y_test.shape)
# modeling
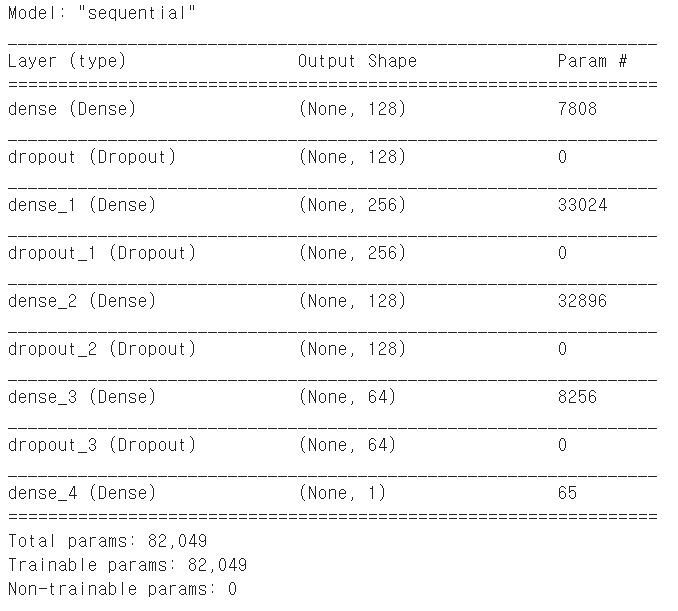
model = Sequential()
model.add(Dense(128, input_shape=(X_train.shape[1],), activation='relu'))
model.add(Dropout(dropout_ratio))
model.add(Dense(256, activation='relu'))
model.add(Dropout(dropout_ratio))
model.add(Dense(128, activation='relu'))
model.add(Dropout(dropout_ratio))
model.add(Dense(64, activation='relu'))
model.add(Dropout(dropout_ratio))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mean_squared_error')
model.summary()
model_fit = model.fit(X_train, Y_train,
batch_size=batch_size, epochs=epoch,
verbose=verbose)
- 2차원 형태 X input, input_shape에는 feature 개수인 5개만
- MSE 기준으로, optimizer는 adam
# prediction
Y_train_pred = model.predict(X_train)
Y_test_pred = model.predict(X_test)
# evaluation
result = model.evaluate(X_test, Y_test_pred)
if scaler != []:
Y_train = scaler.inverse_transform(Y_train)
Y_train_pred = scaler.inverse_transform(Y_train_pred)
Y_test = scaler.inverse_transform(Y_test)
Y_test_pred = scaler.inverse_transform(Y_test_pred)
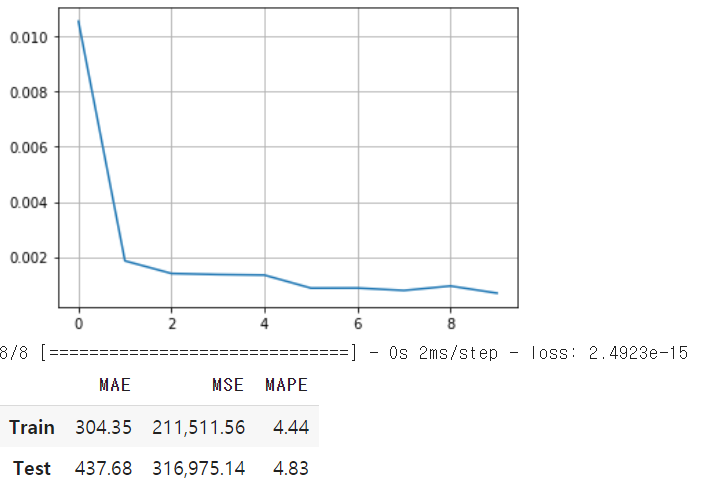
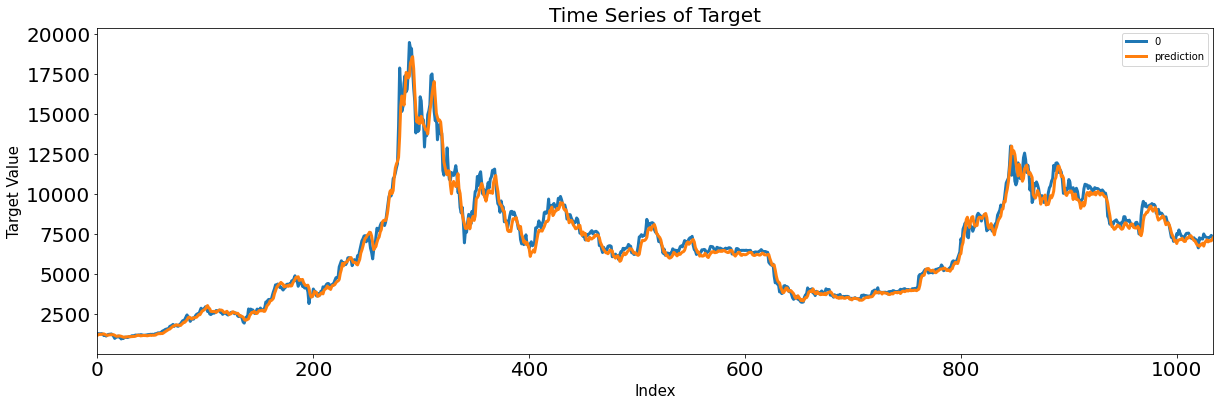
Score_MLP, Residual_tr, Residual_te = evaluation_trte(pd.DataFrame(Y_train), Y_train_pred.flatten(),
pd.DataFrame(Y_test), Y_test_pred.flatten(), graph_on=True)
display(Score_MLP)
- scaler.inverse_transform으로 변형했던 스케일을 원래 스케일로 복원해 모델 평가
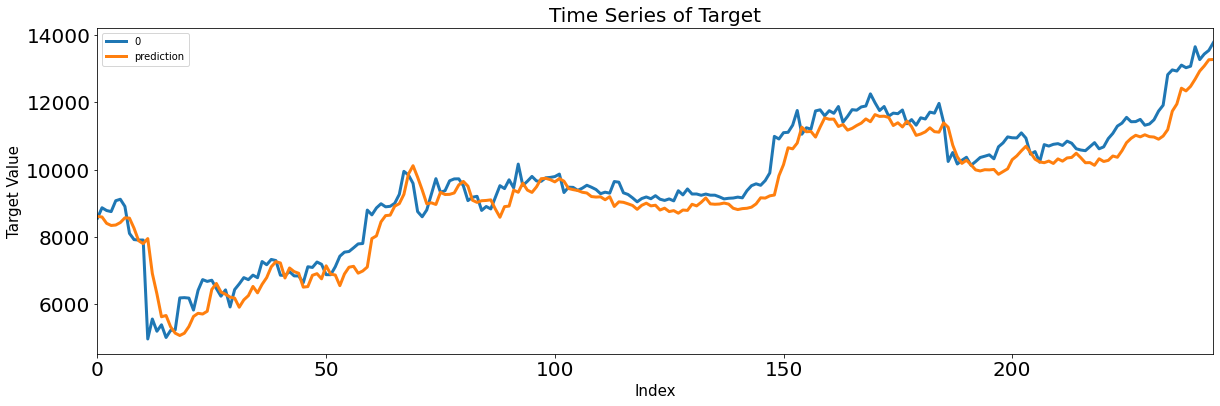
2. RNN
# RNN
model = Sequential()
model.add(SimpleRNN(128, input_shape=(X_train.shape[1], X_train.shape[2]), return_sequences=True, activation='relu'))
model.add(Dropout(dropout_ratio))
model.add(SimpleRNN(256, return_sequences=True, activation="relu"))
model.add(Dropout(dropout_ratio))
model.add(SimpleRNN(128, return_sequences=True, activation="relu"))
model.add(Dropout(dropout_ratio))
model.add(SimpleRNN(64, return_sequences=True, activation="relu"))
model.add(Dropout(dropout_ratio))
model.add(Flatten())
model.add(Dense(1))
model.compile(optimizer='adam', loss='mean_squared_error')
model.summary()
model_fit = model.fit(X_train, Y_train,
batch_size=batch_size, epochs=epoch,
verbose=verbose)
- simpleRNN layer
- reshape 없이 input 3차원 그대로 ( feature 갯수, 차원 )
- return_sequences = True 로 받아와 이전 hidden layer에서 출력된 output 다시 받아옴
- 3차원 feature를 flatten으로 2차원으로 변형
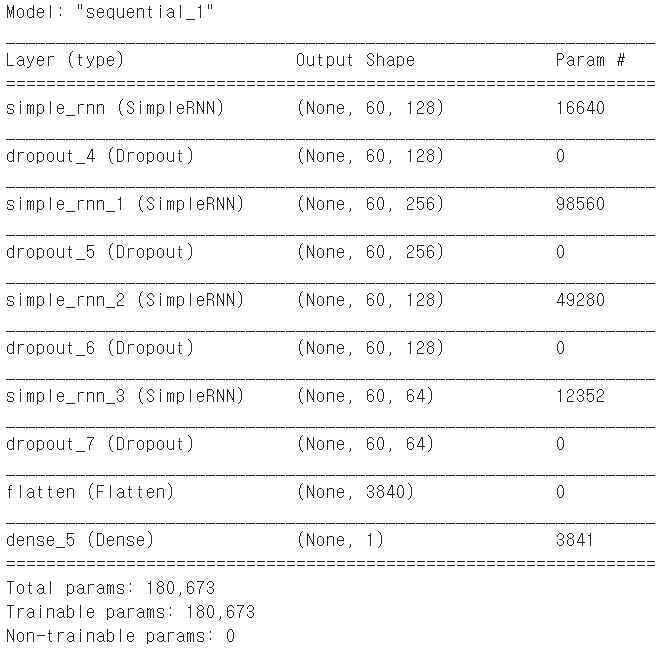
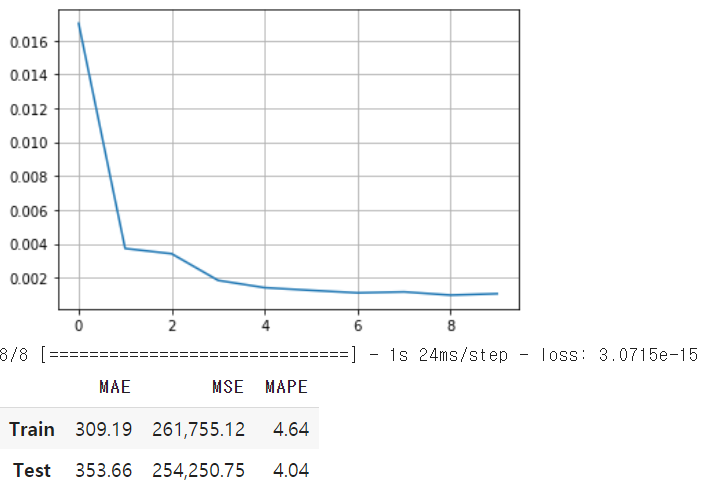
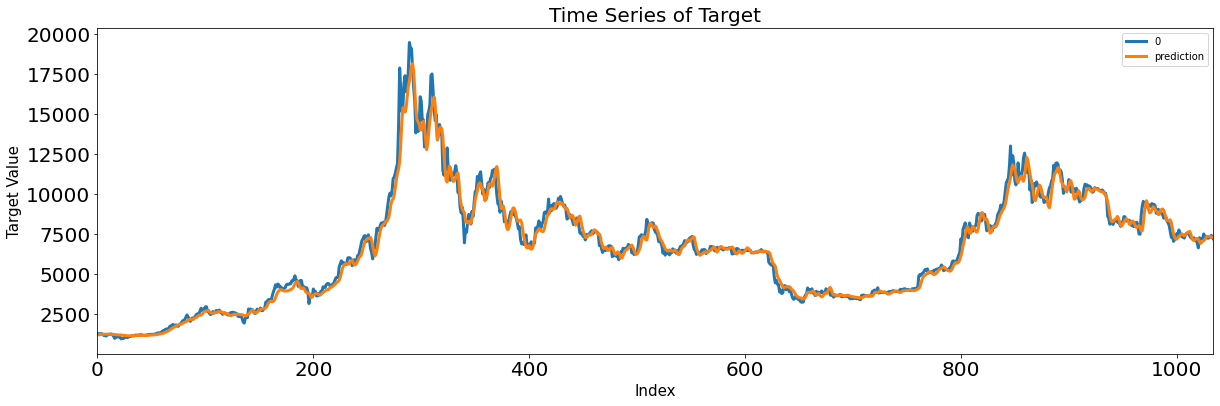
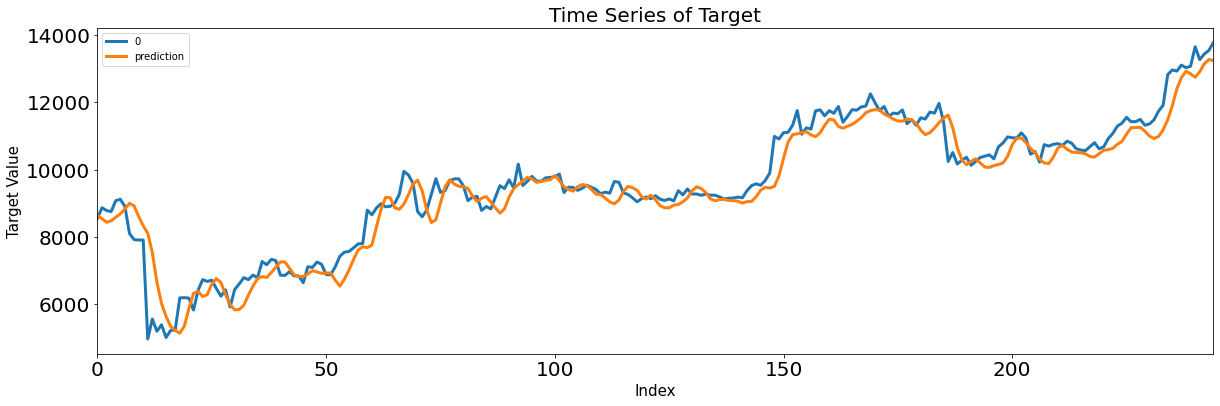
3. LSTM
# LSTM
model = Sequential()
model.add(LSTM(128, input_shape=(X_train.shape[1], X_train.shape[2]), return_sequences=True, activation='relu'))
model.add(Dropout(dropout_ratio))
model.add(LSTM(256, return_sequences=True, activation="relu"))
model.add(Dropout(dropout_ratio))
model.add(LSTM(128, return_sequences=True, activation="relu"))
model.add(Dropout(dropout_ratio))
model.add(LSTM(64, return_sequences=False, activation="relu"))
model.add(Dropout(dropout_ratio))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mean_squared_error')
model.summary()
model_fit = model.fit(X_train, Y_train,
batch_size=batch_size, epochs=epoch,
verbose=verbose)
- LSTM layer
- reshape 없이 input 3차원 그대로 ( feature 갯수, 차원 )
- return_sequences = True 로 받아와 이전 hidden layer에서 출력된 output 다시 받아옴
- return_sequence = False -> 시퀀스의 2차원 형태로 출력, flatten 사용하지 않아도 됨

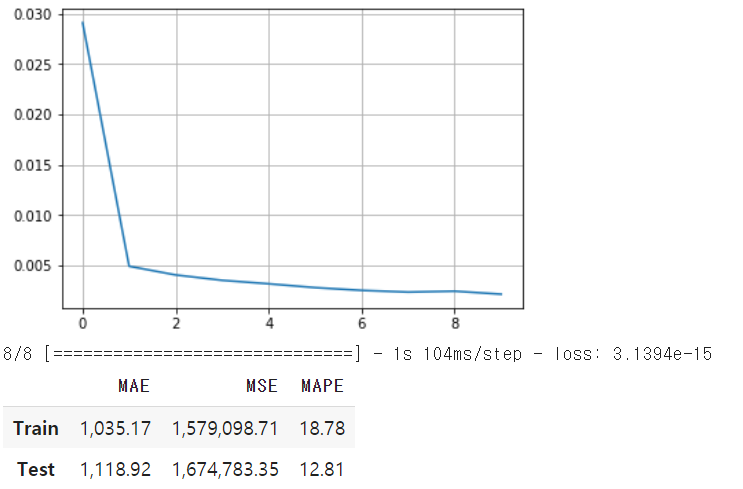
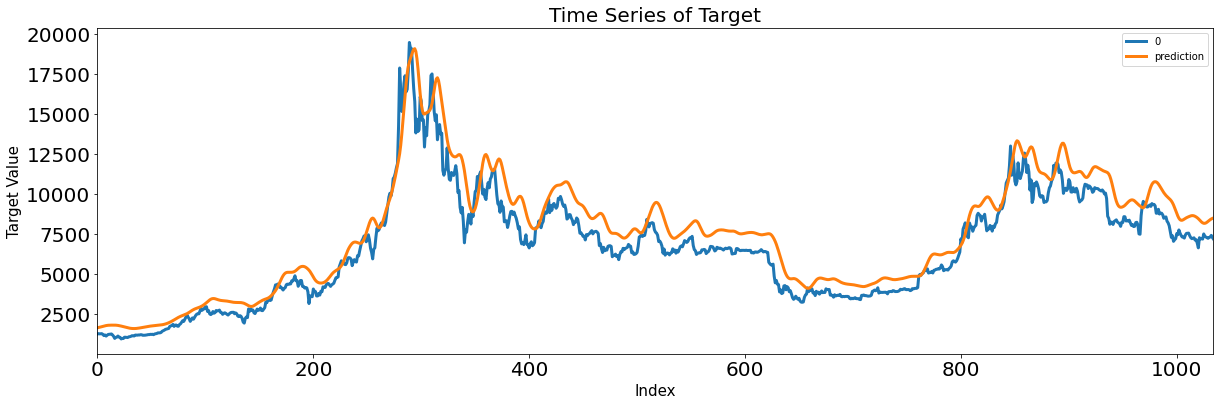
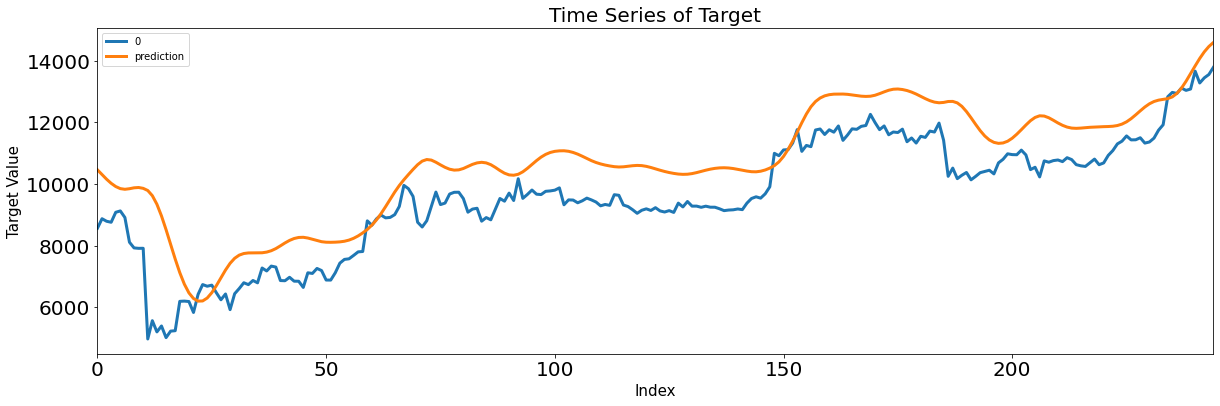
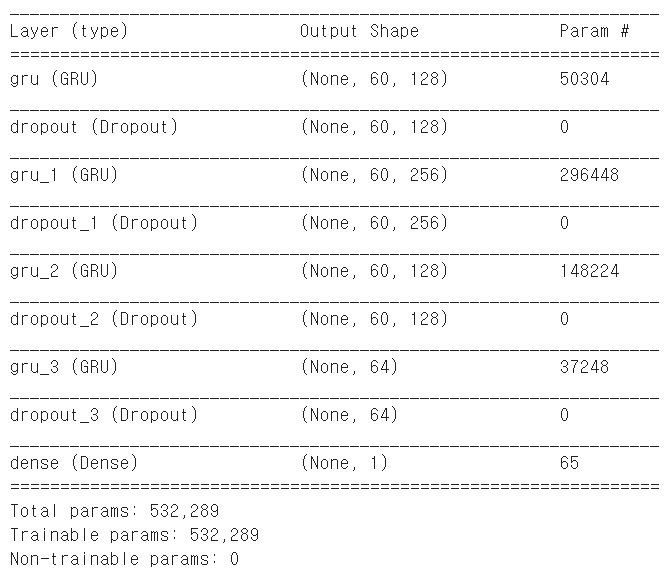
4. GRU
# GRU
model = Sequential()
model.add(GRU(128, input_shape=(X_train.shape[1], X_train.shape[2]), return_sequences=True, activation='relu'))
model.add(Dropout(dropout_ratio))
model.add(GRU(256, return_sequences=True, activation="relu"))
model.add(Dropout(dropout_ratio))
model.add(GRU(128, return_sequences=True, activation="relu"))
model.add(Dropout(dropout_ratio))
model.add(GRU(64, return_sequences=False, activation="relu"))
model.add(Dropout(dropout_ratio))
model.add(Dense(1))
model.compile(optimizer='adam', loss='mean_squared_error')
model.summary()
model_fit = model.fit(X_train, Y_train,
batch_size=batch_size, epochs=epoch,
verbose=verbose)
- GRU layer
- reshape 없이 input 3차원 그대로 ( feature 갯수, 차원 )
- return_sequences = True 로 받아와 이전 hidden layer에서 출력된 output 다시 받아옴
- 3차원 feature를 flatten으로 2차원으로 변형
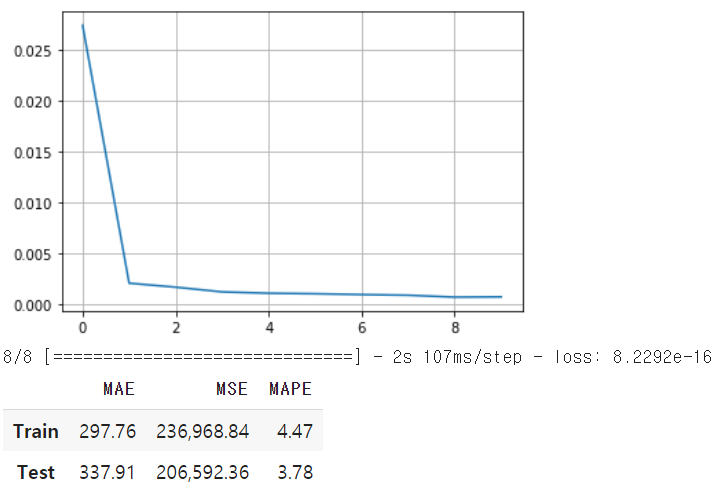
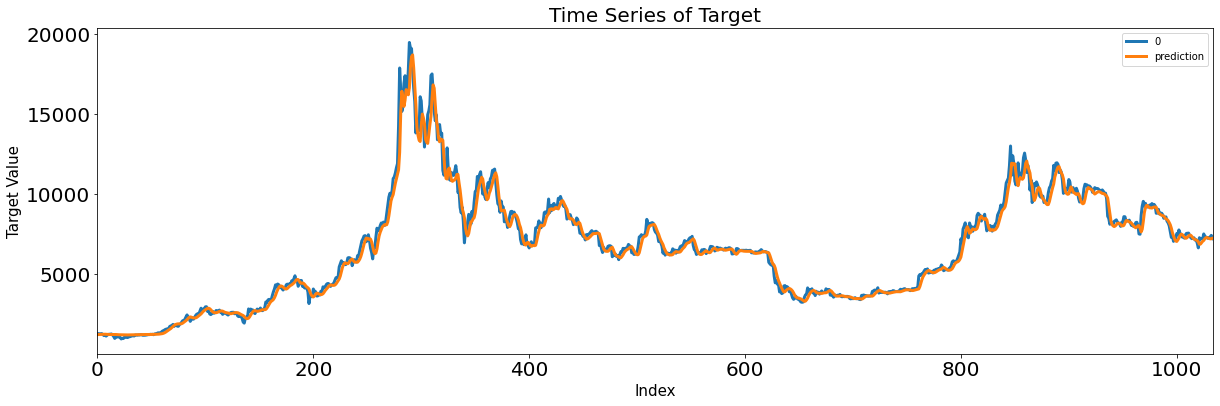
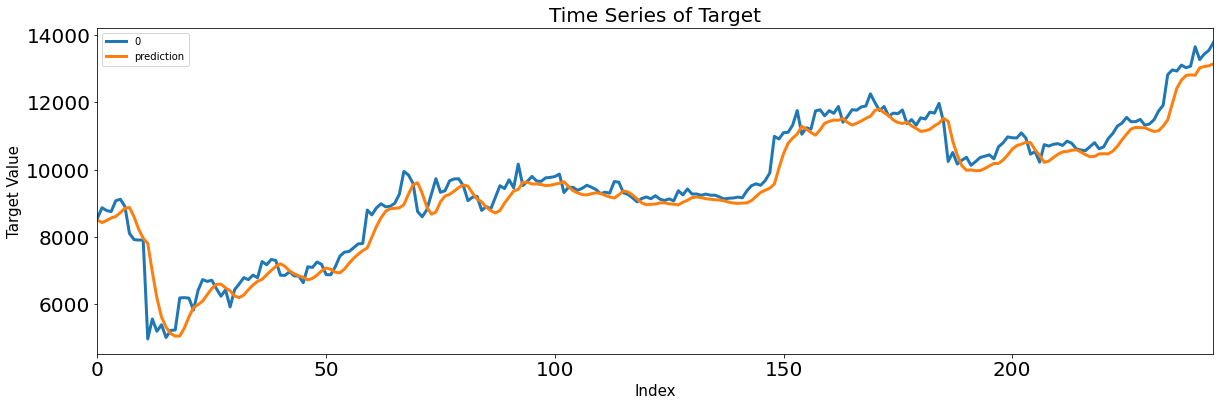
- GRU가 가장 좋은 성능 보였음
+ 참고 자료 및 출처
김경원 < 파이썬을 활용한 시계열 데이터 분석 A-Z 강의 > ( 패스트캠퍼스 강의 )
'Analysis > Time series' 카테고리의 다른 글
| Lecture 18. 시계열 딥러닝 알고리즘 (0) | 2021.05.02 |
|---|---|
| Lecture 17. 비선형 확률과정 (0) | 2021.04.06 |
| Lecture 16. 다변량 선형확률과정 (0) | 2021.04.05 |
| Lecture 15. Kaggle 자전거 수요 예측 (SARIMAX / Auto-ARIMA) (0) | 2021.04.05 |
| Lecture 14. Kaggle 자전거 수요 예측 (RF/SARIMA) (0) | 2021.04.03 |




댓글