- 머신러닝 분석으로 수요 예측
- 시계열 분석으로 수요 예측 - SARIMA
0. 데이터 로드
Bike Sharing Demand
Forecast use of a city bikeshare system
www.kaggle.com
- 2년치 데이터로 시간당 데이터 축적
- Y는 count, 즉 총 렌탈횟수 예측하기

1. 데이터 전처리
raw_all = pd.read_csv('./Bike_Sharing_Demand_Full.csv')
# Feature Engineering
# to_datetime, asfreq, seasonal_decompose(trend, seasonal), fill_na,
# Day ,Week, diff, Year, Quater, Month, Hour, DayofWeek, lag1, lag2 .. etc
raw_fe = feature_engineering(raw_all)
Lecture 3. 시계열 데이터 패턴 추출
0. 데이터 로드 케글 데이터 - 자전거 수요 www.kaggle.com/c/bike-sharing-demand/data Bike Sharing Demand Forecast use of a city bikeshare system www.kaggle.com raw_all = pd.read_csv('Bike_Sharing_Dema..
5ohyun.tistory.com
Lecture 8. 시계열 데이터 전처리
Condition Number Condition number가 클수록 변수들간의 scaling이 필요하거나 다중공선성이 나타남을 의미함 Condition number를 감소시켜야 함 1. Scaling 2. 다중공선성 제거 - VIF, PCA를 통해 변수 선택 3...
5ohyun.tistory.com
# 02/29 이 비어있어 2/28과 3/1 데이터 step 추출해 채워줌
target = ['count_trend', 'count_seasonal', 'count_Day', 'count_Week', 'count_diff']
raw_fe = raw.copy()
for col in target:
raw_fe.loc['2012-01-01':'2012-02-28', col] = raw.loc['2011-01-01':'2011-02-28', col].values
raw_fe.loc['2012-03-01':'2012-12-31', col] = raw.loc['2011-03-01':'2011-12-31', col].values
step = (raw.loc['2011-03-01 00:00:00', col] - raw.loc['2011-02-28 23:00:00', col])/25
step_value = np.arange(raw.loc['2011-02-28 23:00:00', col]+step, raw.loc['2011-03-01 00:00:00', col], step)
step_value = step_value[:24]
raw_fe.loc['2012-02-29', col] = step_value
# Data Split
Y_colname = ['count']
X_remove = ['datetime', 'DateTime', 'temp_group', 'casual', 'registered']
X_colname = [x for x in raw_fe.columns if x not in Y_colname+X_remove]
criteria = '2012-07-01'
raw_train = raw_feR.loc[raw_feR.index < criteria,:]
raw_test = raw_feR.loc[raw_feR.index >= criteria,:]
Y_train_feR = raw_train[Y_colname]
X_train_feR = raw_train[X_colname]
Y_test_feR = raw_test[Y_colname]
X_test_feR = raw_test[X_colname]
# lag1, lag2
target = ['count_lag1', 'count_lag2']
X_test_feR = X_test_feR.copy()
for col in target:
X_test_feR[col] = Y_test_feR.shift(1).values
X_test_feR[col].fillna(method='bfill', inplace=True)
X_test_feR[col] = Y_test_feR.shift(2).values
X_test_feR[col].fillna(method='bfill', inplace=True)
# Scaling
scaler = preprocessing.Normalizer()
scaler_fit = scaler.fit(X_train_feR)
X_train_feR = pd.DataFrame(scaler_fit.transform(X_train_feR), index=X_train_feR.index, columns=X_train_feR.columns)
X_test_feRS = pd.DataFrame(scaler_fit.transform(X_test_feR), index=X_test_feR.index, columns=X_test_feR.columns)
# Select variable - VIF
# from statsmodels.stats.outliers_influence import variance_inflation_factor
vif = pd.DataFrame()
num_variables = 12
vif['VIF_Factor'] = [variance_inflation_factor(X_train_feRS.values, i) for i in range(X_train_feRS.shape[1])]
vif['Feature'] = X_train_feRS.columns
X_colname_vif = vif.sort_values(by='VIF_Factor', ascending=True)['Feature'][:num_variables].values # select 12
X_train_feRSM, X_test_feRSM = X_train_feRS[X_colname_vif].copy(), X_test_feRS[X_colname_vif].copy()
2. 데이터 분석
(1) 머신러닝 분석으로 수요 예측 - Random Forest
# Random Forest
fit_reg6 = RandomForestRegressor(n_estimators=100, random_state=123).fit(X_train_feRSM, Y_train_feR)
pred_tr_reg6_feRSM = fit_reg6.predict(X_train_feRSM)
pred_te_reg6_feRSM = fit_reg6.predict(X_test_feRSM)
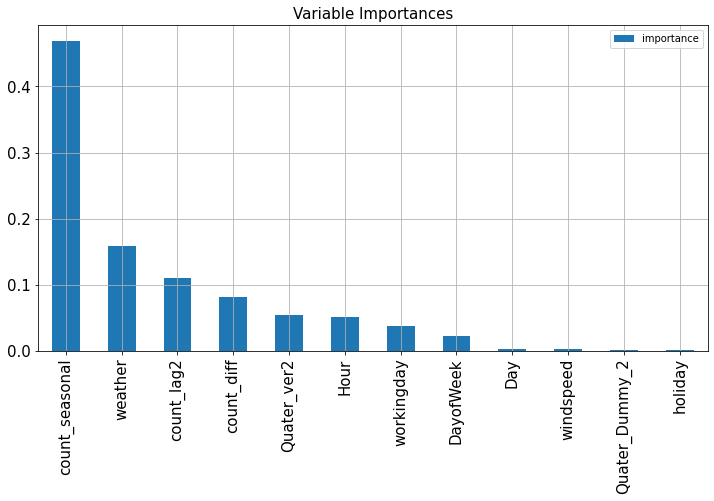
# Variable Importances
Variable_Importances = pd.DataFrame([fit_reg6.feature_importances_],
columns=X_train_feRSM.columns,
index=['importance']).T.sort_values(by=['importance'], ascending=False)
Variable_Importances.plot.bar(figsize=(12,6), fontsize=15)
plt.title('Variable Importances', fontsize=15)
plt.grid()
plt.show()
(2) SARIMA 시계열 분석으로 수요 예측
# Parameter Setting
logarithm = False
trend_diff_order = 0
seasonal_diff_order, seasonal_order = 0, 12
# 비정상성 데이터의 정상성 변환
if logarithm: # 로그 변환
Y_train_feR = np.log(Y_train_feR).copy()
Y_test_feR = np.log(Y_test_feR).copy()
# SARIMA
fit_ts_sarimax = sm.tsa.SARIMAX(Y_train_feR, trend='c', order=(1,trend_diff_order,1),
seasonal_order=(1,seasonal_diff_order,1,seasonal_order)).fit()
pred_tr_ts_sarimax = fit_ts_sarimax.predict()
pred_te_ts_sarimax = fit_ts_sarimax.get_forecast(len(Y_test_feR)).predicted_mean
pred_te_ts_sarimax_ci = fit_ts_sarimax.get_forecast(len(Y_test_feR)).conf_int()
# 다시 정상성 데이터의 비정상성 변환
if logarithm: # 지수 변환으로 다시 비정상성
Y_train_feR = np.exp(Y_train_feR).copy()
Y_test_feR = np.exp(Y_test_feR).copy()
pred_tr_ts_sarimax = np.exp(pred_tr_ts_sarimax).copy()
pred_te_ts_sarimax = np.exp(pred_te_ts_sarimax).copy()
pred_te_ts_sarimax_ci = np.exp(pred_te_ts_sarimax_ci).copy()
3. 분석 결과 비교
Lecture 4. 시계열 데이터 분리 및 회귀분석
데이터 준비 - 비시계열 vs 시계열 비시계열 - Simple, K-fold, Holdout 시계열 - Time series cross-validation ( 단기, 장기 ) 회귀분석 (1) 검증지표 R^2 t-검정 : 독립변수와 종속변수 간의 선형관계 신뢰성..
5ohyun.tistory.com
(1) ML 분석 결과 - Random Forest
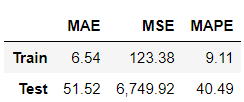
# ML Evaluation
Score_reg6_feRSM, Resid_tr_reg6_feRSM, Resid_te_reg6_feRSM = evaluation_trte(Y_train_feR, pred_tr_reg6_feRSM,
Y_test_feR, pred_te_reg6_feRSM, graph_on=True)
display(Score_reg6_feRSM)

(2) TS 분석 결과 - SARIMA
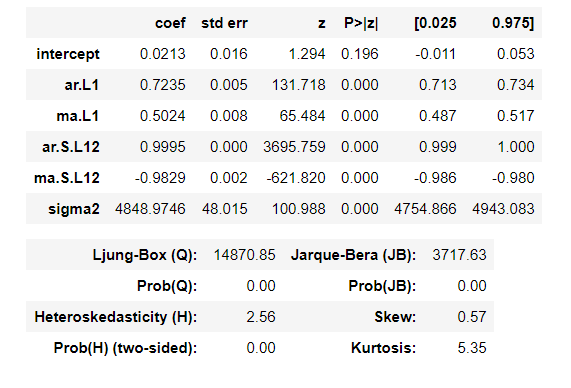
# TS Evaluation
display(fit_ts_sarimax.summary())
Score_ts_sarimax, Resid_tr_ts_sarimax, Resid_te_ts_sarimax = evaluation_trte(Y_train_feR, pred_tr_ts_sarimax,
Y_test_feR, pred_te_ts_sarimax, graph_on=True)
display(Score_ts_sarimax)
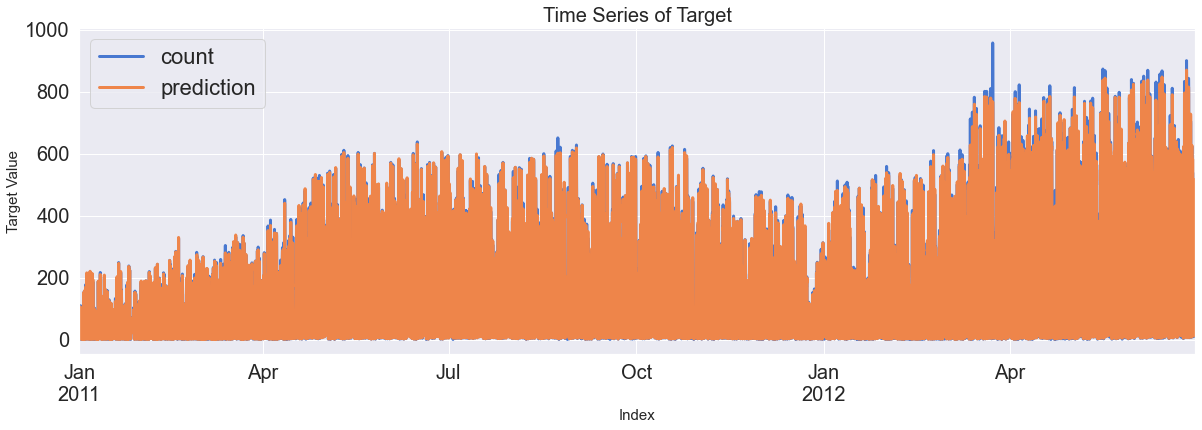
ax = pd.DataFrame(Y_test_feR).plot(figsize=(12,4))
pd.DataFrame(pred_te_ts_sarimax, index=Y_test_feR.index, columns=['prediction']).plot(kind='line',
xlim=(Y_test_feR.index.min(),Y_test_feR.index.max()),
linewidth=3, fontsize=20, ax=ax)
ax.fill_between(pd.DataFrame(pred_te_ts_sarimax_ci, index=Y_test_feR.index).index,
pd.DataFrame(pred_te_ts_sarimax_ci, index=Y_test_feR.index).iloc[:,0],
pd.DataFrame(pred_te_ts_sarimax_ci, index=Y_test_feR.index).iloc[:,1], color='k', alpha=0.15)
plt.show()


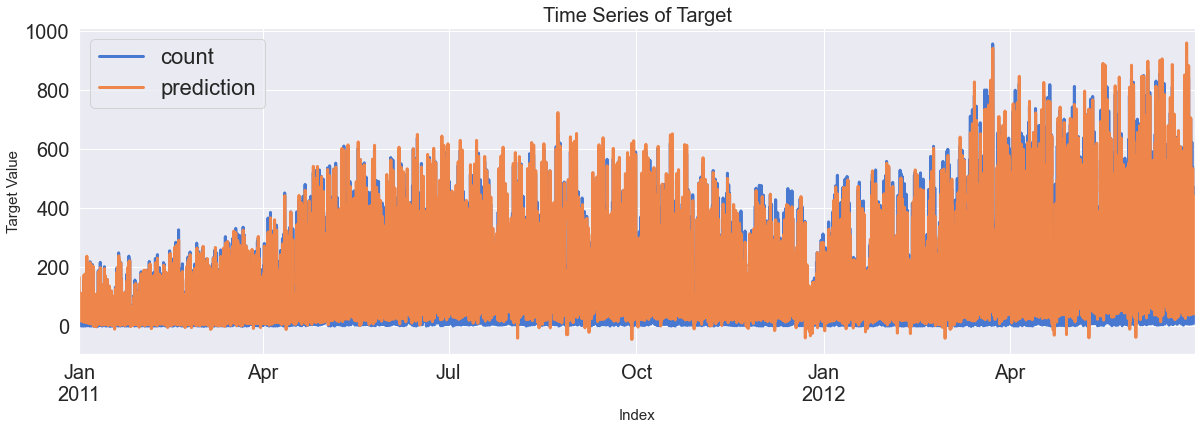
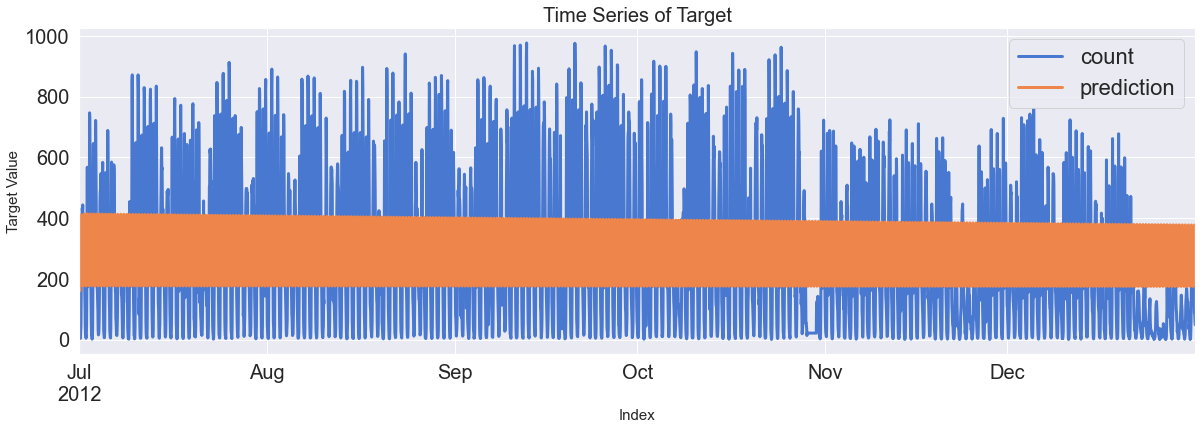
4. 잔차 분석 비교
(1) ML 잔차 분석 결과
# ML Error Analysis
error_analysis(Resid_tr_reg6_feRSM, ['Error'], X_train_feRSM, graph_on=True)
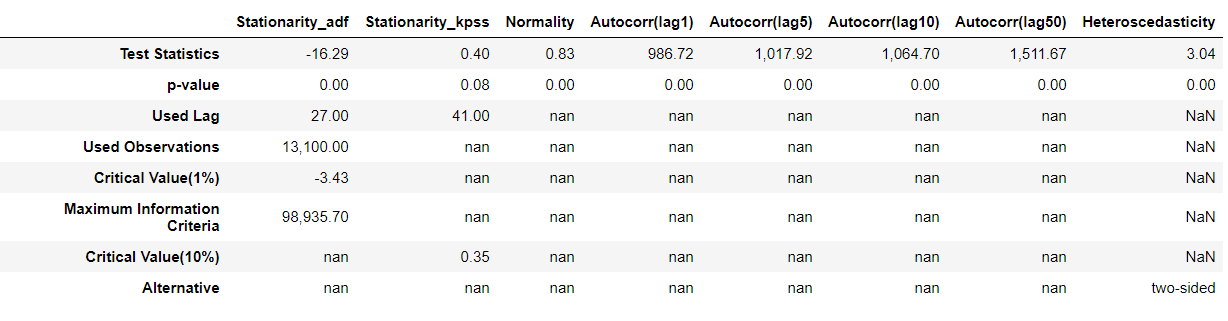
(2) TS 잔차 분석 결과 - SARIMA
# TS Error Analysis
error_analysis(Resid_tr_ts_sarimax, ['Error'], Y_train_feR, graph_on=True)

+ 참고 자료 및 출처
- 김경원 < 파이썬을 활용한 시계열 데이터 분석 A-Z 강의 > ( 패스트캠퍼스 강의 )
'Analysis > Time series' 카테고리의 다른 글
| Lecture 16. 다변량 선형확률과정 (0) | 2021.04.05 |
|---|---|
| Lecture 15. Kaggle 자전거 수요 예측 (SARIMAX / Auto-ARIMA) (0) | 2021.04.05 |
| Lecture 13. 선형확률과정 분석실습 (0) | 2021.04.03 |
| Lecture 12. 적분 선형확률과정 (0) | 2021.04.01 |
| Lecture 11. 단순 선형확률과정 (0) | 2021.03.29 |




댓글