정규화 회귀분석 알고리즘
- 정규화 : overfitting 을 막기 위해 파라미터 값을 줄이는 것, 계수의 크기를 제한하는 방법
- 파라미터 값에 제약을 줌
1. Standard Regression
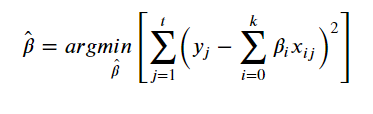
- 식을 최소화하는 베타값을 찾아야 함 - RSS 최소화
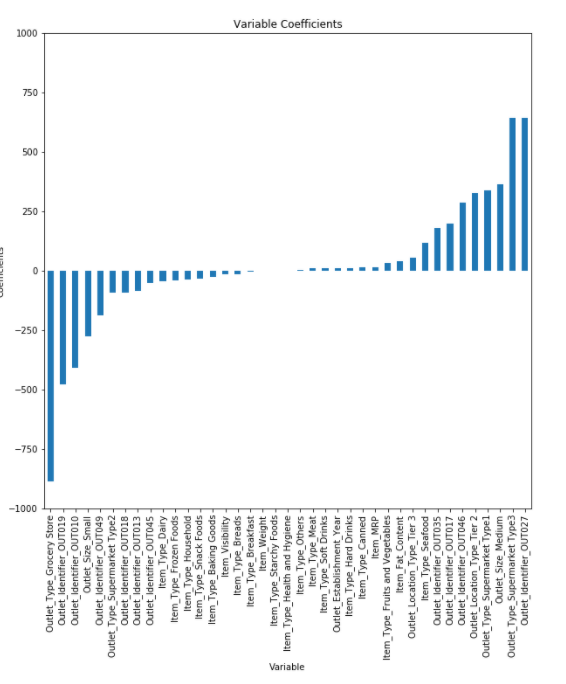
2. Lidge Regression
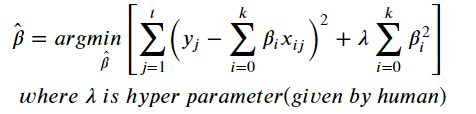
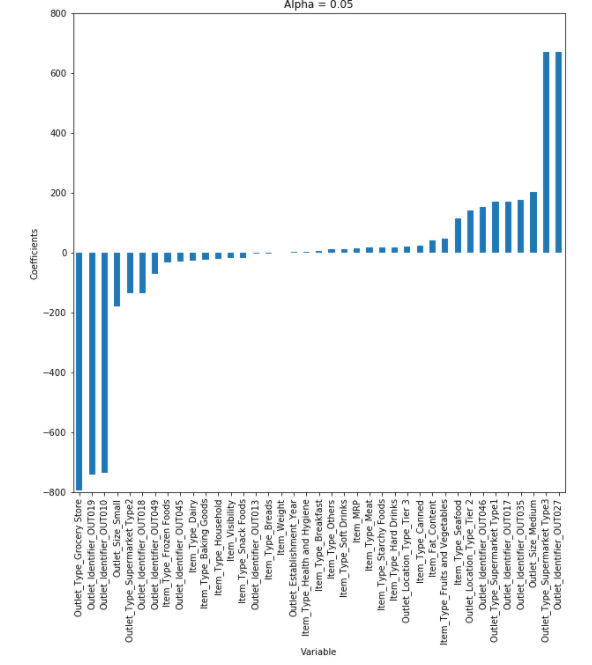

- RSS + 페널티식 (제곱합)
- 베타를 제곱합하므로 큰 베타값에 민감하게 반응함
- 큰 베타값은 줄여야하므로 하이퍼파라미터(람다)를 크게 하면 가중치값이 작아짐 -> 베타에 0 가까운 값 부여
- 하이퍼파라미터를 작게 하면 가중치값이 커짐
- 베타 스케일을 조정해 현실성있는 계수 추정
- 모든 변수를 사용하기 때문에 계수가 작아지고 모형 복잡도가 줄어들며 계수가 많을수록 효과적이진 않지만 다중공선성을 방지할 수 있음
from sklearn.linear_model import Ridge, Lasso, ElasticNet
fit = Ridge(alpha=0.5, fit_intercept=True, normalize=True, random_state=123).fit(X_train, Y_train)
pred_tr = fit.predict(X_train)
pred_te = fit.predict(X_test)
3. Lasso Regression
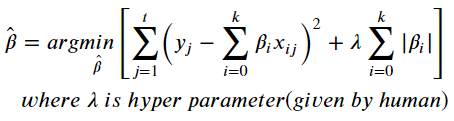
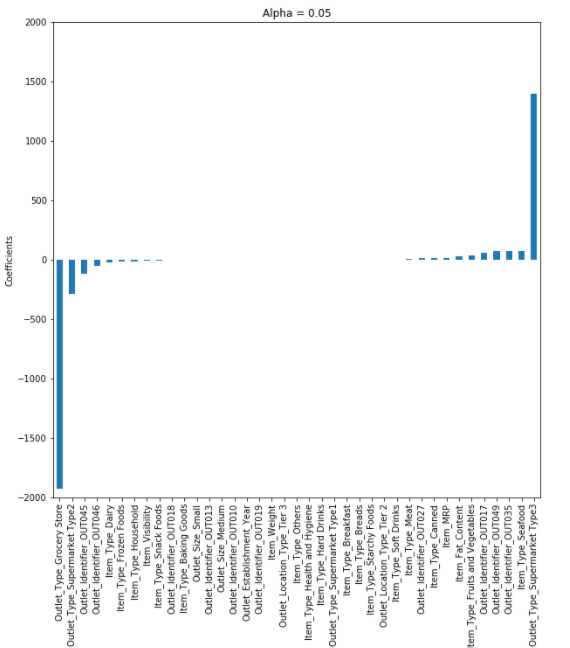

- RSS + 페널티식 (절대값 합)
- 베타가 크든지 작든지 무관함
- 효과가 없는 x를 베타가 0이 되게 만들어 변수 선택 효과
- 다중공선성 제거 효과 (Ridge에 비해서는 낮음)
fit = Lasso(alpha=0.5, fit_intercept=True, normalize=True, random_state=123).fit(X_train, Y_train)
pred_tr = fit.predict(X_train)
pred_te = fit.predict(X_test)
4. Elastic Net
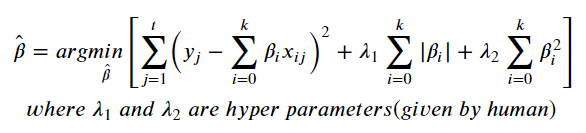
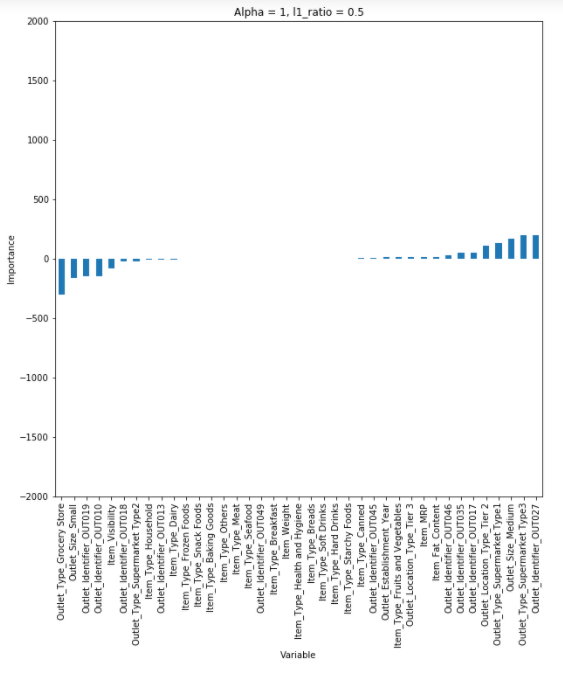
- RSS + 페널티식(절대값 합 + 제곱합)
- Lasso와 Ridge의 장점을 모두 활용하기 위해 사용
- 적은 데이터셋으로는 효과 낮음
fit = ElasticNet(alpha=0.01, l1_ratio=1, fit_intercept=True, normalize=True, random_state=123).fit(X_train, Y_train)
pred_tr = fit.predict(X_train)
pred_te = fit.predict(X_test)
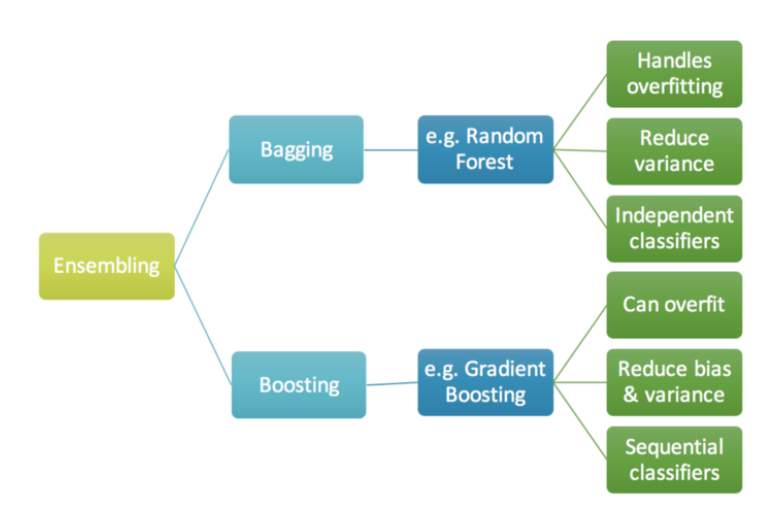
Bagging과 Boosting
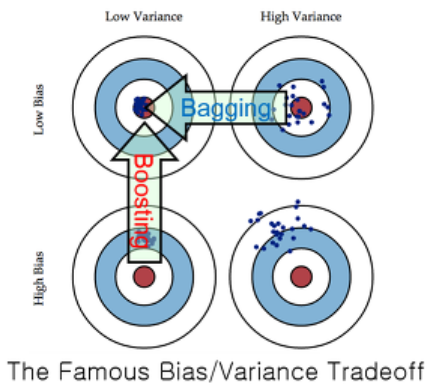
1. Bagging
- Bias가 낮은 모델들을 통해 variance를 줄임
- RandomForest : DecisionTree의 CLT
# DecisionTree
fit = DecisionTreeRegressor().fit(X_train, Y_train)
pred_tr = fit.predict(X_train)
pred_te = fit.predict(X_test)
# RandomForestRegressor
fit = RandomForestRegressor(n_estimators=100, random_state=123).fit(X_train, Y_train)
pred_tr = fit.predict(X_train)
pred_te = fit.predict(X_test)
fit.feature_importances_
# Prediction Effect of Variables
Variable_Importances = pd.DataFrame([fit.feature_importances_],
columns=X_train_feRSM.columns,
index=['importance']).T.sort_values(by=['importance'], ascending=False)
display(Variable_Importances)
Variable_Importances.plot.bar(figsize=(12,6), fontsize=15)
plt.title('Variable Importances', fontsize=15)
plt.show()
- 트리가 잘 나눠지는 기준 ( X와 y의 영향력 기준 XX )
2. Boosting
- Variance가 낮은 모델들을 합쳐 Bias를 줄임
- 잔차진단
- AdaBoost, GBM : 잔차를 분석해 알고리즘 성능을 향상시킴

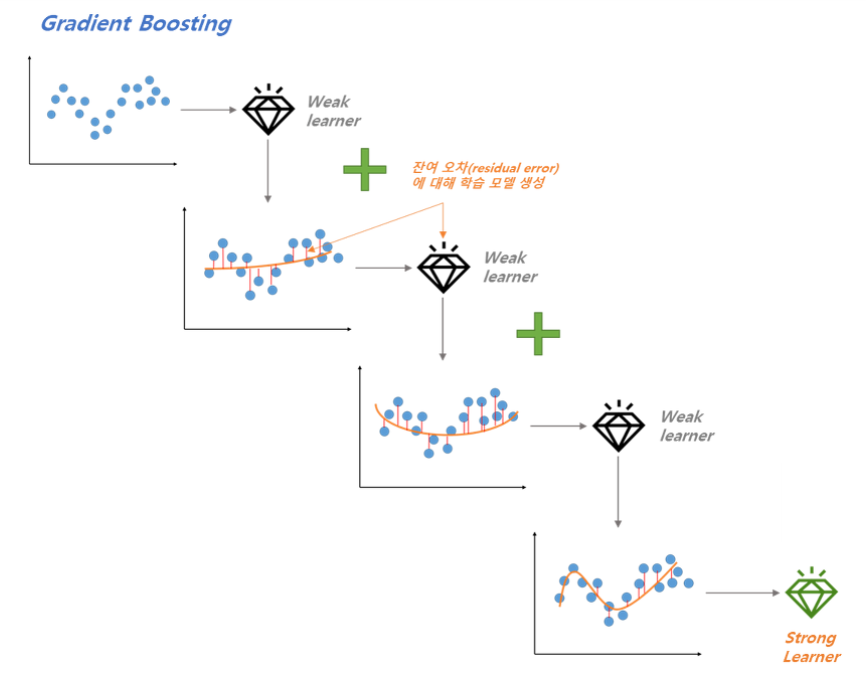
# GradientBoostingRegression
fit = GradientBoostingRegressor(alpha=0.1, learning_rate=0.05, loss='huber', criterion='friedman_mse',
n_estimators=1000, random_state=123).fit(X_train, Y_train)
pred_tr = fit.predict(X_train)
pred_te = fit.predict(X_test)
# XGBoost
fit = XGBRegressor(learning_rate=0.05, n_estimators=100, random_state=123).fit(X_train, Y_train)
pred_tr = fit.predict(X_train)
pred_te = fit.predict(X_test)
# LightGMB
fit = LGBMRegressor(learning_rate=0.05, n_estimators=100, random_state=123).fit(X_train, Y_train)
pred_tr = fit.predict(X_train)
pred_te = fit.predict(X_test)
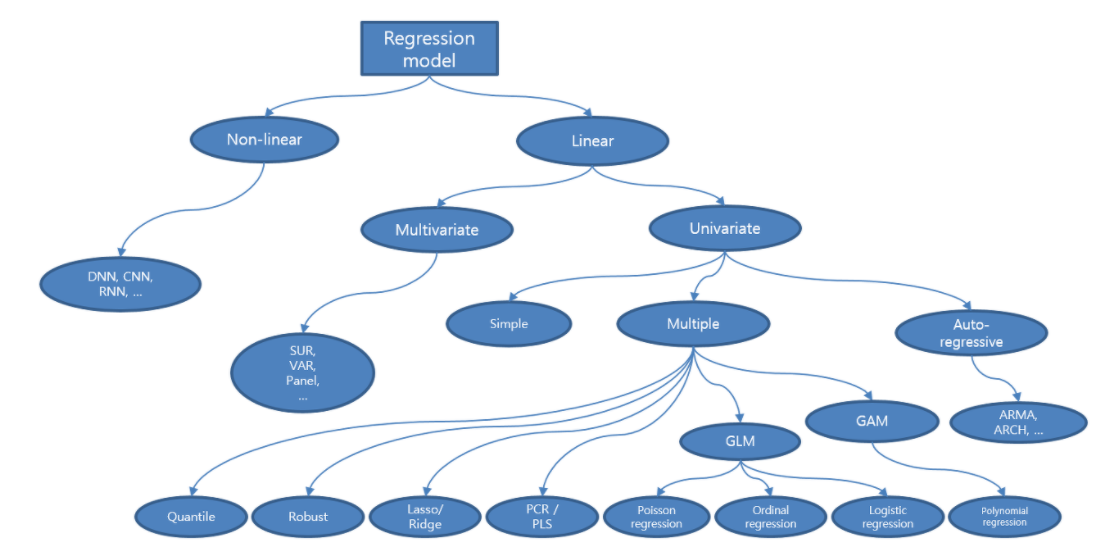
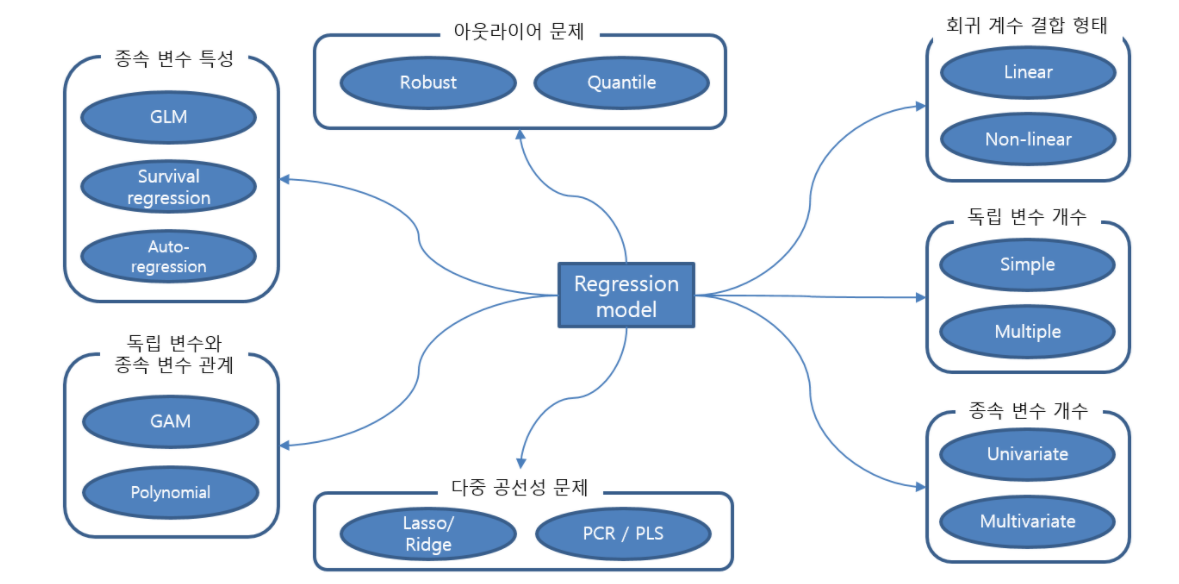
목적별 회귀분석 알고리즘
- 특정한 목적이나 한계를 개선하기 위해 만들어진 알고리즘
+ 참고 자료 및 출처
- 김경원 < 파이썬을 활용한 시계열 데이터 분석 A-Z 강의 > ( 패스트캠퍼스 강의 )
'Analysis > Time series' 카테고리의 다른 글
| Lecture 11. 단순 선형확률과정 (0) | 2021.03.29 |
|---|---|
| Lecture 10. 타겟 데이터 정상성 변환 (0) | 2021.03.27 |
| Lecture 8. 시계열 데이터 전처리 (0) | 2021.03.18 |
| Lecture 7. 잔차진단 (0) | 2021.03.16 |
| Lecture 6. 분석성능 확인 (0) | 2021.03.16 |




댓글